I wanted to write about the consistently hot topic of “severity vs Priority” – which I’ve noticed that many people seem to get confused about, and that there is so much conflicting information about out there on the web.
It’s been bugging me (excuse the pun) for quite some time now. And even the great, almighty bug management system that is Jira seems to have gotten it wrong (they don’t even include a severity field by default, and the priority field seems to contain severity options…?).
My interpretation of “Severity” is how severe the bug is with regards to the system, the user and the business. So this is the impact of the bug that you find, with regards to the system. Whether it is something that has minimal impact, such as a spelling issue in a paragraph of text, or something more severe such as an application or server error screen that appears when clicking a button… The severity scale that I like to use is: Blocker, Critical, Major, Average, Minor and Trivial.
Priority on the other hand, I interpret to be the importance that the defect is fixed from the business’ perspective. So in effect, this is setting a level of importance in which the defect should be fixed purely from the context of how it affects the business. I see this as being a business decision, so testers might not necessarily set this, or they might, but with the intention of updating this after discussions/triages with the other members of the team. The scale of priority options that I like to use is: High, Medium and Low.
It’s important for us to take context into account too when thinking about a defect’s severity and priority. We have to understand the circumstances of the defect, the conditions in which the defect occurs, the frequency that it occurs, who is affected by the bug, what effects that the bug might have on the business, etc… We have to understand the defect as fully as possible before we can apply sensible severity and priority levels for it.
I’ve had many discussions on the subject of “Severity vs Priority”, and there are endless discussions/debates online on the subject. From having these discussions and getting involved in these online groups about this topic, I got thinking about how, when prioritising a defect to be fixed, we definitely need to take both the severity and priority of the defect into account when thinking about an overall prioritisation for dealing with fixing bugs… What I mean by this is that the “Priority” level (that is set based on the business effects) can’t really be the ideal scale on its own to fix bugs without taking into account the severity factor – for example, if you have multiple bugs that are a high priority, you need to additionally think about the severity of each of these bugs and also take this factor into account to determine which bugs to approach fixing first, right?
With this in mind, I had the idea of slightly modifying Eisenhower’s “Time Management Process Model”, to be relevant to “severity” and “priority”:
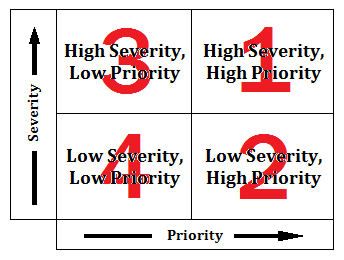
So, high severity and high priority items would be the main issues to attend to first. Second would be the low severity and high priority items, followed by the high severity and low priority items, and finally the low severity and low priority items.
Some examples of bugs that fit into each quadrant that spring to mind might be:
- High severity and high priority = a “server error” page appears when the “login” button is clicked on the login screen of a company’s web app – the functionality of the button is completely broken, therefore it is a severe defect. The high priority is down to the fact that users cannot log in to the web app at all, which affects the business immensely.
- Low severity and high priority = a company’s logo image doesn’t appear properly on their web application – the bug has not affect the operability of the web app in any way. It is purely a cosmetic bug, but has an urgency to be fixed due to it being the company’s logo.
- High severity and low priority = this could be a broken link that causes a “server error” page to be displayed, but the link might be on a screen that is unimportant, or the link might only be very rarely clicked by a user.
- Low severity and low priority = this might be a spelling issue that’s within a large paragraph of text that is rarely read by the users.
There are many more examples that you can find online.
One thing that I have noticed though is that context is key, and that context most likely isn’t detailed in any examples!! Even in my own examples I have not explained any details around each of my example bugs at all, and one tiny bit of detail can completely change the face of the bug which would more than likely change the severity or priority (or both).
For example, if we take the “low severity and low priority” example (the spelling issue in a large paragraph that users hardly ever read)… If this paragraph happened to be within some legislation text on the website, that is usually displayed to a user when they are required to “accept” these legal terms, then this spelling issue could be a huge problem for the business! In this context, the severity might still be low, but the priority would certainly be high.
So to sum up (before this blog post gets any longer), I believe that both “severity” and “priority” are individual aspects of a bug that should be set independently from each other (tester should set the severity and the business stakeholders should set the priority). Additionally, in order to set the severity and priority, you need to investigate the bug and gather as much information about it as possible in order to have some accuracy in the values that you set…
I believe that both of the “severity” and “priority” aspects need to be taken into account when working out a true prioritisation for fixing the defects, which is where the adaptation of Eisenhower’s “Time Management Process Model” comes in (which I hope you find useful!!).
What’s your thought on this topic?

Dan,
First, I completely agree that Jira gets this wrong. It’s completely absurd and I have no idea how they’ve confused the definition of the two words. Australian English isn’t that different to British English!
A couple of other observations:
1) When assessing both properties I think it is extremely important to bear in mind whether a workaround is present, and if so, the cost in terms of both user time to implement it and subsequent effects on the data.
2) If a data loss / data corruption issue is found, but a business process continues to function, it may be tempting from the business perspective to de-prioritise it (“it’s not causing us any problems, it’s just an IT issue, we can sort it out later, it’s just data”). It’s our responsibility as developers and testers to push back on this and ensure that a sensible severity is set (usually easy) but also that a sensible priority is set.
It’s beyond my comprehension how there are any debates over this. To me it is entirely obvious that both of these properties are necessary and easily differentiated.
LikeLike
Thanks for the comment Ben!
I agree – the situation as a whole has to be taken into account. If a convenient workaround exists, then the priority might be reduced accordingly.
If it’s a data corruption/data loss issue, then I’d be inclined to think that this is quite severe. It means that something is broken badly enough to wipe data, or corrupt data. But of course you need to take context into account – what is the data that is being corrupted? how often does it occur? who does it affect? is it a very difficult scenario to reproduce in order for the data to become corrupted? etc…
I think part of the confusion within the debates online lies with some of the gumph out there about severity and priority on the web. It’s hell for people that try to self learn about stuff like this via the web! And the fact that a company like Atlassian can even get it wrong doesn’t bode well for people who don’t know the difference either!
LikeLike
A few thoughts here (having spend many years struggling with the same questions).
Sometimes, your industry helps you define the severity levels. Aerospace & Telcom are two where I’ve worked with “standard” definitions of severity.
In commercial world, I’ve come to think of these along several dimensions:
Severity: (Critical, Major, Minor) describes the consequences of the defect if it occurs. Critical = data loss, exposure of private data, failure to log in, system crash, etc…
Frequency: How often, or probability of occurrence. Always to extremely remote in obscure features.
Impact to customers: Customer’s perception of issue. (high, med, low)
Impact to system/process: How invasive would the fix be? Essentially a measure of how much regression test is required, or describes the impact to your testing (ie. blocker)
These factors, taken together, usually point to a priority. (order & sequence of bug fixing). Two examples, a Critical severity is almost always a high priority. Also, a low severity, but high customer impact is usually a high priority.
We usually only track 1 or 2 of these dimensions, otherwise, the bug management process gets too complex for managers to deal with. Usually, boiling everything down to priority is most effective to help the org make decisions. Engineers/testers think in 2 dimensions, managers in 1 dimension.
LikeLike
“Engineers/testers think in 2 dimensions, managers in 1 dimension.”
Seriously? When you were a development manager and a project manager, did you stop thinking in two dimensions?
—Michael B.
LikeLike
Well, if after so many years we are still discussing the difference between these two may be it’s time to start over.
I believe this came due to two reasons: 1) It makes a very good interview question just like difference between Verification and Validation but does it matter? and 2) some early stupid bug management systems introduced these two terms and seems like Jira is still confused.
What I believe now is that we should not have these two separate fields but rather one (name it Priority may be). The tester can provide some initial thought about it but let the Project Manager or who ever is responsible make the call so as whether to fix this bug in current release or not.
LikeLike
Hi Majd! Thanks for the comment!
Do you think it’s feasible to simply have 1 field to represent both severity and priority?
To me, these are 2 different things, and both are relevant information about a defect. I think if you didn’t record them separately, then the only way to relay this information is within the bug description, which makes it far more difficult to report on…
LikeLike
I think it might work. See, any information that we provide with a bug is to make a decision: “Should we fix this bug for current release?”. So of what is the use of a bug that has high severity but put on as lower priority by the Owner? For one of our projects, we are tinkering with TFS and introduced a single field called ‘Risk’. Tester sets it and the Owner can reset if needed.
By the way, thanks for bringing up this topic as it pops up here and there.
LikeLike
Hi Dan,
I was asked the same question by my colleague which urged me to write the following post as to clarify the difference and usage between the two: http://xnovo.org/2013/01/03/severity-vs-priority/
Generally, there are situations in which you might use only 1 of the options (i.e.: small number of teams or the number of defects is quite small thus it makes sense to use a combined value covering both Severity and Priority as not to get it complicated where it’s not needed).
Indeed, JIRA is not perfect in that domain though being an Issue Tracker (besides handling Project Management activities, etc), but there are a couple of things I wanted to mention here:
– Though not being shipped with both Severity & Priority out of the box you are still able to add a custom field (Severity in our case) on demand
– You might consider integrating QA specific Add-Ons that would help organize the process better (though still most of them inherit JIRA’s Priority field only, but you should be able to configure additional fields the same way as you might do this directly in JIRA though you will have more execution/flexibility/tracking options available):
https://marketplace.atlassian.com/plugins/com.thed.zephyr.je
https://marketplace.atlassian.com/plugins/com.atlassian.bonfire.plugin
https://marketplace.atlassian.com/plugins/plugin.jet
Regards,
Stas
LikeLike
Michael B.
Thanks for calling me out on the statement: “Engineers/testers think in 2 dimensions, managers in 1 dimension.”
This is not true, but is a provocative statement that I frequently use when coaching test leaders. With the fuller context of a coaching session, I explain how important it is to present data in a form that is most appropriate to the audience.
In project reviews, especially towards the end of the project, the leaders typically are thinking “how many of the known bugs need to be fixed before release?” (*) This is typically a 1 dimension presentation: “We have 5 P1 bugs, 15 P2, and 24 P3, the P1 & P2 bugs must be fixed before release, the P3 bugs should be fixed, but we can negotiate”. Severity and Impact are used by the quality leader to help make that distinction, and the leader should definitely be prepared to “click-down” one level to show the multi-dimensional view. But in the interest of brevity and focus, I recommend leaders present the status in a manner that answers the question asked by the project leadership team.
Another principle that I recommend to quality leaders, full transparency. In practice, I present the core set of quality metrics, abstracted appropriately to the audience, but also link to the detailed data source. In my case, its a JIRA dashboard for the project, which contains roughly 15 views of the defect data.
Thanks for allowing me to explain in more detail
John
* we “should” fix all of them, but often low severity/low impact bugs get deferred
LikeLike
Well Explained !!!
LikeLike
informative
LikeLike
HI dan.
Your explanation was good but i need a seperate explanation for High/medium/low priority and high/medium/low severity
LikeLike
Hey, Dan. Hope you don’t mind me commenting on a year-old blog post.
I liked it! A lot! The examples you gave for “examples of bugs that fit into each quadrant” are almost identical to ones I usually give. It’s good to get confirmation.
Another way I sometimes explain Severity and Priority is by using synonyms and analogy. I use the word “seriousness” instead of “severity”, and the word “importance” instead of “priority”. Then, I talk about the seriousness and importance of a fire by describing the size of the fire (big, small, etc.) and considering what is on fire (my house, your hair, etc.). This helps folks understand the relationship between severity and priority and what they mean together.
Cheers!
LikeLiked by 1 person
Hi Damian! Thanks for the comment! Its never too late to comment on a blog post 🙂
Thats actually a good analogy. The “what is on fire” part is interesting as I initially thought about ‘Seriousness’ as I read it too. But I can see how it also relates to ‘Importance’.
And also, thinking about it, its interesting that everyone values different things so will all have different levels of importance for each thing (I might find my tablet and laptop important things to save in a house fire, my partner would probably try and save some of her clothes in her wardrobe)…
So importance should stem from the people who matter (stakeholders, customers, users, etc).
But it’s a nice analogy! 🙂
LikeLike
I have question that if one defect is of high severity and other defect is of high priority, and as a tester i have only one day left to test the defect.
then which defect i should test first.
LikeLike
So, the tester sets the severity based on the impact of the problem. How severe is it…
The business sets the priority based on how urgency in resolving the problem.
Therefore, I’d test the higher priority problem first, as that is the request of the business. (This is assuming that /both/ of the problems have been resolved for your to test them both).
Also on a separate note – if you are short of time, then make that information explicit to your product owner and project manager – talk to them about the difficult timescale that’s restricting your testing. Tell them that you will test to the best of your abilities within the timescale, but when you’re detailing your testing, you should say what you couldn’t test as well as what you did test too.
LikeLike
Reblogged this on SDLC Tools and commented:
I was going to write a whole blog post on the fact that JIRA appears to be wrong with the default values for its Priority field (they’re not priorities, they’re severities). Dan, however, appears to have done a great job already so there’s no point.
Please just read his excellent article instead.
LikeLiked by 1 person