Welcome to the final part on this series about the relationship between Testing and Product Risks.
In part one, I discussed the idea and benefits of talking about testing product risks instead of talking about types of testing. If you missed that post, you can view it here.
In part two, I then went on to discuss how I uncover product risks through testing, and shared a model about that. You can see that post here.
In this third and final post, I’m going to talk about proactive quality and reactive quality. Bug prevention and bug detection. Testing pre and post code being written and how the risks and variables that we discover can help us stem better design to mitigate those risks, with some models to help explain the various feedback loops from our testing activities.
Mitigating risks through design
The idea of bug prevention isn’t new, but it’s still not mainstream – it’s still relatively unknown in the industry. There is confusion surrounding it too, as there are various communities that would claim bug prevention means that we don’t need testing. However, it’s actually testing ideas that allow us to uncover the information about risks that we can then feed in to refactoring our artefacts and designs and code design to be able to prevent the risks becoming problems.
Here’s a loose SDLC model that helps me to explain the feedback loops that we get from our continuous testing activities throughout the SDLC.
(Note: this SDLC model is not depicting using a waterfall methodology. These activities within the SDLC inevitably run in parallel as we have many small slices of features that we work on simultaneously when working using an agile methodology).
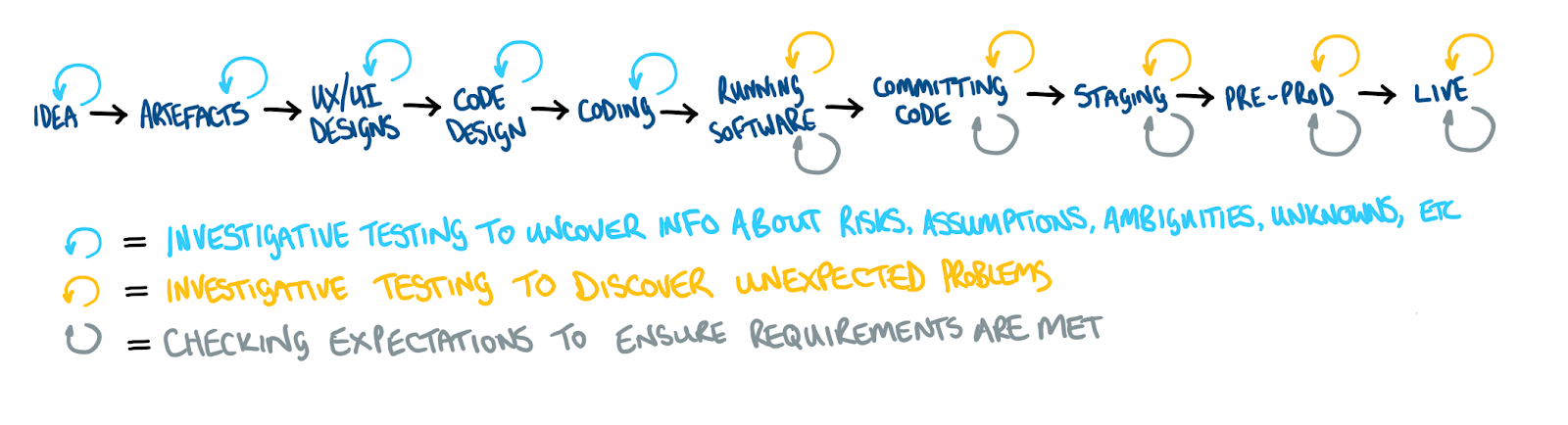
It’s all investigative testing in the first half of the SDLC (because it’s all done before any code being developed, so there’s no software to check against the expectations of how it should work). But similarly to the exploratory testing that is done against a software product, when we test the ideas, artefacts, UX & UI designs, code design, architecture designs, etc, the purpose is to uncover information. It’s just that that information uncovered is in the form of identified risks. and our testing notes are risk maps.

It makes sense that some of those risks we can mitigate through design. Some we can’t! And for those, we can factor them in to test charters and investigate the product to see if the risks have manifested into problems.
Bug prevention and bug detection (proactive quality and reactive quality)
It’s clear to see the distinction between testing to identify risks (or in other words, problems within our ideas, artefacts, designs, thinking, etc…) and testing the software driven by the risks we’ve identified to identify problems in the software.
But it’s not as simple as saying that all testing done after code is written is only about finding problems based on our pre-discovered risks…
This is because it’s impossible to think of every unknown relating to that small feature / MVP / SMURFS that we’re creating. There will always be complete unknowns (that is; unknowns that we remain unaware of). Even when we put these testing processes in place to strive to become aware of unknown risks and variables, we’ll definitely uncover lots of things, but we’ll also remain ignorant to lots of other things too. So even when the code is written, and we’re investigating the software, we’ll discover information that relates to risks and variables that we hadn’t thought of previously.
In the book: “Ignorance: How it drives science”, Stuart Firestein uses a really useful analogy of ignorance being like “ripples on a pond”. He says: “As the knowledge grows, so does the ignorance. It’s not that ignorance is transformed into knowledge. The more important process goes in the other direction. Knowledge leads us to higher-quality ignorance, always trying to settle on better and better questions”.

I like this quote a lot. It applies to our ideas and information that we collect regarding our software, all the way throughout the SDLC. The more the ripples of knowledge expand, the more we reveal and become aware of further unknowns.
So, yes, the difference between preventing bugs in our software and detecting bugs in our software does relate to that aspect of “before and after code being written”, but a better way to look at it is that anything we do discover about risks and variables before we write any code, gives us the opportunity to stem better design to mitigate those risks. With the realization that we’ll also continue to uncover more unknown risks and variables past the point of writing code, and even past the point of releasing the feature into production.
The risks of not thinking about risks
Hopefully the benefits of thinking this way regarding the relationship between our testing activities and product risks.
It’s still surprising how many software teams don’t have a focus on product risks for their testing though. From speaking to teams in this position, I’ve noticed that they might think of good test ideas, but struggle to relate that back to the purpose of the test being a type of product risk that they are testing for.
Additionally, because of this, these teams that I have spoken to also struggle with involving testers prior to any code being written.
With the purpose of testing that’s done before any code is written being
to uncover information about the different risks and variables that relate to the ideas and designs about the software solution (think about the feedback loops on the first half of the SDLC model), then if you don’t have that perspective regarding product risks, then it’s extremely likely that you’re testing right now is purely reactive, to find problems, by testing the code or the software once it’s written.
When I challenged those teams on that, the response was focused around TDD – writing tests to help with code design. But the problem with that is that those tests being written are still scripted tests to assert our expectations, and therefore still aren’t run until some code has actually been written in order for the tests to compare the expectation against. And these tests are automated, and therefore can’t uncover any information that’s unexpected (i.e. risks and variables). For that, you need to apply the investigative testing approach.
Some of those teams did experiment with introducing this approach, and shuffling their processes to inject testing throughout the entire SDLC, putting some focus on product risks. The results were huge for those teams! They could see clearly the value of testing in this way, and they had far less bug fixing cycles since the faster feedback loops from the early testing was helping them to stem better design to mitigate some of the risks they uncovered too.
What’s your experience with product risks?
Do you think about risks like this? If not, do you recognize some of the challenges of not thinking about risks in this way?
I hope you have the ability to try to practice thinking about testing this way. If you do, I’m always keen to hear your stories of how that goes!

Dan, thanks for putting this blog series together. Could you please provide examples of the experiments the teams used to introduce the investigative test approach to earlier phases of the SDLC?
LikeLiked by 2 people
I never thought about this. Very insightful!
LikeLike
Good Post and had a better understanding. Thanks for sharing
LikeLike