UPDATE: Thanks to John Stevenson for his feedback of the model, I’ve updated the model appropriately to represent the fact that checking activities also inform our testing, (as John described in the comments below). Also, thanks again to everyone else who has reviewed and fed back on the model too.
One of the biggest problems that is hitting the testing industry at this point in time is the misconception that automation can replace testing. Michael Bolton, James Bach and others within the testing industry have been working hard to try and dispel this misconception, but I still see daily struggles in most companies that I see today. Not just with the management within those organisations or with the developers or other project members, but with the vast majority of the people in the testing or automation roles within these organisations too.
Many testers believe that they need to learn how to automate in order to stay in a job. And many people online (some who supposedly consider themselves as industry experts) believe this too and preach it in their posts…
I read Michael and James’ 10,000 word white paper which offers some insightful lessons on further differences between “testing” and “checking” along with where automation fits within context driven testing. I enjoyed reading this white paper, and I’ve tried to hand out this white paper to many organisations that I know have problems understanding this. But these people still have these same problems. And when asking about whether people have actually read the paper, the general response was either that it is too long or that they don’t like the term “checking”… (Many people in automation roles see this as demeaning to the work they do in their role – they see the word “checking” similarly to how I view the word “manual”).
So how do I simplify this? How do I get people to start understanding?
Initially, I started to change my language. I still spoke about “testing” and “checking”, but I didn’t speak about them directly… I spoke about them via their relationship with information. I think people started to understand when I spoke about information and how investigation uncovers more information, and how we can then check to confirm any information that we have.
After having a few lengthy conversations, I decided that it would be far easier to talk about information’s relationship with testing and checking via a model.
So without further ado, here is the model:
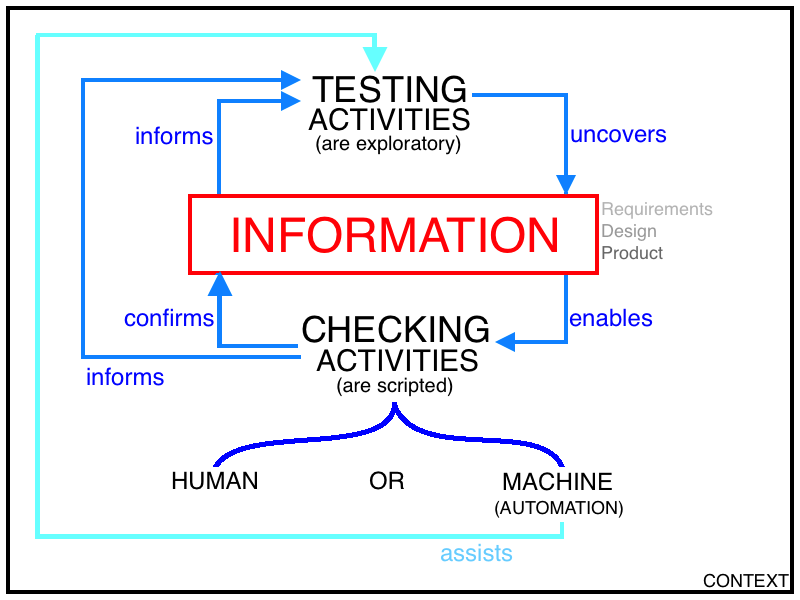
It’s fairly rudimental right now. I have intentionally kept it basic, without adding information about the different types of knowledge, the artifacts that we create from our information/knowledge, or anything about reporting on our testing of checking activities, etc.
It also might not seem new, or might seem obvious to some people – the big difference with this model is that I’m intentionally putting the focus on INFORMATION.
Let me explain the model:
– Information –
This is our currency with software projects and products – Information regarding our requirements, our designs & artifacts, our feature and products, our platforms, our processes… Information is the centre of it all.
– Testing Activities –
Testing is an investigatory activity (exploration) that has the effect of uncovering more information. We can explore requirements through questioning them as a team. We can explore the design of the product through questioning the wireframes and further discussions regarding the UX and UI design of the product. And of course, we can explore the product to uncover more information about it.
Also, the information that we uncover then informs our testing. It helps us stem more ideas. The previous question asked or lesson learned regarding what we have tested will stem and influence the next question or idea that we think of.
It’s also important to remember that there are many activities involved in the lifecycle of a product. Exploratory testing is just one. Code reviewing is another. Requirements analysis is a testing activity conducted by the whole team ideally…
– Checking Activities –
If we think about what we do when we check a claim made by any source of information regarding a product, then it’s clear that the information that we are using is enabling to perform that check. If we didn’t have that information, we couldn’t assert whether that expectation is true or not.
There are many checking activities that we conduct against the product. A prime example is regression checking, where we are asserting our expectation that new features we are introducing to our software have not adversely affected pre-existing features that we have already built. Or when we check our expectations of the behaviour of single lines of code under the conditions that we know about.
And these checking activities are usually scripted. Either in a “steps” and “expectation” format for a human to perform these checks, or in code for a computer to automatically check these expectations that we write as assertions.
Additionally, checking activities can also inform our testing too – As John Stevenson has indicated below: a failing check could give some information that you may need to do some more investigation and testing. Equally, a suite of checks all being green could stem some investigation to discover what you may not be checking or to investigate if the checks in place are incorrect.
– Automation can assist our testing –
The term “tool assisted testing” is one that Richard Bradshaw has been using for a long time. And it’s one that Michael and James used in their white paper too. I used to use the term throwaway scripts myself, but now I much prefer Richards terminology. But the main thing that is important to remember: although automation can assist our testing with data generation or manipulating the software in order to get from A to B to be able to start testing from B to uncover new information – automation is assisting our testing. It’s not performing our testing at all.
This all relates to the “5 orders of ignorance” regarding information.
I’m increasingly referring to the 5 orders of ignorance when discussing this model with people too. For those not familiar with the 5 orders:
- The 0th order of ignorance is: KNOWLEDGE – This is our knowns. Our explicit information.
It’s the information that we can use to enable our checking. - The 1st order of ignorance is: LACK OF KNOWLEDGE – This is our unknowns. It’s things that we are aware that we do not know. When we ask questions such as “what if…” or “what about…”, then we know that we don’t know the answer, so we can test to uncover the answer. To test, we ask the question – be it of a product owner regarding a requirement, or of the product through operating the product and observing how it responds.
- The 2nd order of ignorance is: LACK OF AWARENESS – This is our unknown unknowns. Its ultimately when we are unaware that we don’t know something. Therefore we cant ask questions about it. We don’t even know to ask questions about it as we are unaware of it. And this is caused by:
- The 3rd order of ignorance: LACK OF PROCESS – This is where we have no process (or activity) in place that enables us to uncover information (gaining awareness) regarding our unknown unknowns.Testing activities are this process…
If you think of exploring a requirement: Rob Lambert had a great blog post a while ago about an activity that he ran with his team, where he asked them to think of all the possible purposes of a brick. If that was a requirement and I shouted out “use it to break a car window”, then that would most likely trigger an idea in your head about either smashing other windows for different reasons (a house window to gain entry to the house), or other uses for the brick in the car (e.g. using it to hold down the accelerator). But if we didn’t have this activity of testing occurring, then would we even think about these possible uses?Or if you think about a product: If we were pairing and I mentioned an idea to try and put a double barrelled surname with a dash in the surname field (i.e. “Harding-Rolls”), that will most likely stem an idea in your head, perhaps about adding an apostrophe in the surname (“O’Brien”) or even a foreign character surname (“張”). These may have previously been unknown unknowns (2nd order) that we have triggered to become unknowns that we are now aware of (1st order) through our testing activity, that we can then perform a test by asking the question of the product to transfer this unknown into knowledge (0th order). - The 4th order of ignorance is: META IGNORANCE – This is cheesy. It’s when there is a lack of awareness of the 5 orders of ignorance. We can ignore this in the context of this post… 🙂
With all this in mind, the last thing to be aware of is CONTEXT. There will always be outside influences from the project, from the product, from the customers and users, from our organisations, from the community, from our environments, etc that will form our contexts that we work in and will influence our testing.
Overall, I think this model (putting the emphasis on information) has helped many people to finally understand the differences between testing and checking. It’s helped those organisations reform their “testing” strategies to actually include investigative testing activities.
And this model isn’t intended to replace anything or annoy anyone. It’s hopefully useful in addition to other models, blogs and articles on this topic – in helping to dispel this misconception that has been haunting the testing industry and affecting software that people use on a daily basis.
I encourage your feedback on the model too. All models are fallible but can be useful, so feedback will help refine the model to help make it more useful.
(A very big thank you to the following people for reviewing and supplying feedback on this model before I published it: Richard Bradshaw, Tony Bruce, Mark Winteringham, Augusto Evangelisti and Lauren Braid)

Dan, I really like your model and I believe that can help people understand the real value of testing, thank you.
I really like it also because it fits perfectly with my vision of testing that involves testing ideas and assumptions (before the product exists). I also use the levels of ignorance metaphor often and explain how testing in all its forms is about reducing ignorance bit by bit. Well done and keep up your research!
LikeLiked by 1 person
Hi Dan
Was good to do a little catch up at testbash. I remember saying I had looked quickly at your model and there was something that did not seem right. Having another look now I remembered what it was,
In your diagram you have testing uncovering information, however could some checking provide you with information as well? For example a failing check could give some information that you may need to do some more investigation and testing. A suite of checks all being green could provide information that something is missing or a need to test more to see what you may not be checking or the checks could be incorrect. Anyway great article and another I am sure to ‘borrow’ and use.
LikeLiked by 1 person
Thanks for the comments John! Interesting points…
I completely agree – Although checking is predominantly to confirm information, it will definitely also inform your testing in the situations that you mentioned!
Drawing this might be a bit challenging… I was intentionally trying to not mention the different types of knowledge as the model can quickly get complicated. :S
Keen to get your input! Do you think a line from “Checking Activities” up to “Testing Activities” labelled “informs” might be sufficient to cover this?
LikeLike
Greetings Dan,
Great model overall. What I think it’s missing, however, is the fact that both human and machine activities “assist” testing. In the model you imply that only machine activities do this.
Freddy Vega
LikeLike
Hi Freddy! How are you? Thanks for the comment!
The update to the model from John’s comment, shows that checking activities inform our testing activities too. During our checking activities, we might spot something that we need to investigate, or one of our checks might fail, which triggers some investigation to uncover more information…
The “assists” line stemming from “automation” is there to represent that automation can also be used to aid our testing activities with things like data set up or getting the system into a state to be able to begin our investigation.
Is this what you mean? I know your comment implies that a script with steps and an expected result can be used to also “assist” our testing, but would we really use scripts for that? Do you have an example that you could share that would offer more explanation?
The way I was looking at it was that if you want to set up some data in the system or get from A to B to be able to begin testing, a script with steps to action and expected results (that is associated with human checking) wouldn’t be useful for that.
It might be useful for people with less domain knowledge to be able to obtain a basic understanding of the expectations surrounding how the system should work. That might help inform their testing in the way that John mentioned, but I’m not sure if that would assist their testing in the way that an automated script might.
But I be missing something completely! 🙂
An example would be great mate!
LikeLike
Hi again Dan! I’m doing great, thanks for asking…
Thanks for explaining what the blue “assist” line is intended to depict. This is exactly what I thought you meant. The reason why I think human and machine can both be utilized to “assist” testing is because more than likely the machine part (which we automated) was being executed by a human at some point in time; this machine part was made more effective by passing the baton to a machine to execute.
Regarding whether we would use a script with steps and an expected result to also “assist” our testing, I would say that yes, when you are using a machine to to this you are, for all intents and purposes, executing a script with an expected result and steps (only that a computer is doing it for you). What is different from a human performing this same steps before they embark on their testing exploration? (besides the obvious difference of human vs machine execution, they are both assisting testing, no?)
Anyways, I do agree with you that more folks should be educating the rest out there about what automation is and isn’t. I think this model is a great way to get that converstation going. Bravo Zulu!
Freddy Vega
LikeLike
Here is something I’ve been saying since the mid 1990’s… Computer Aided Software Test Execution (CASTE), which was a take on the CASE (Computer Aided Software Engineering) paradigm. At that time “automation” was being looked at the same way it is today, as a way to supplant human resources. Well what is old is new again. Einstein was right about the definition of Insanity.
So 20 years later we are still fighting the same battles and dealing with the same myths and misconceptions. And there are those of us old timers who are still working on trying to fix this problem. But between the Marketing/Sales Snake Oil (as James Bach initially spoke about in 1996/1997) and the ever changing landscape of Management and other uninformed people we are having to repeat ourselves constantly.
So welcome to the club. Maybe with more of us raising our voices we can get people to understand the saying of “It’s Automation, Not Automagic!”
Regards,
Jim Hazen
LikeLike
Hi Jim!
Thanks for the comment
Do you think the problem has gotten worse as time has gone on?
I’ve been in the industry over 10 years, but in my early days, I knew that automation misconceptions existed, but they were definitely not as loud as they appear to be these days from my perspective! But I guess there were less blogs/books/conference talks/podcasts/meetups/etc where people could spread the misconceptions and misunderstandings…
I definitely think that it’s important that more people speak up. I think the people in the know should be more obliged to correct those that have misunderstandings about automation and testing if they hear people say something obviously wrong.
But the same applies for other areas of the software industry: “Agile”, “BDD”, etc…
LikeLike
Dan,
Has it gotten worse, well it hasn’t really gotten any better. It has remained the same, but now has more exposure and will hopefully start to change. I have been very vocal for the past few years by posting on blogs and presenting at conferences. But you can only do so much, and I don’t want to come off as a broken record. I try to lead the horse to water and hope that it drinks to use a euphemism. Still a ways to go, but it will hopefully get better.
LikeLike
Excellent post Dan, I really like your model.I recently did a talk that articulated a very similar message(not as well). The one component that appears to be missing from the equation is how we inform our testing I.e. building our understanding of context and gathering feedback from production post release.
LikeLiked by 1 person
Hi Rob. Thanks for the comment! Yeah. Although I have “context” surrounding the model, I haven’t explicitly mentioned the driving of the testing overall. And equally, I haven’t mentioned the reporting of the testing (from a qualitative and quantitative perspective) and our perception of the product’s quality too.
I think I should write another blog about that 🙂
LikeLike
Hi Dan,
Wonderful article!! Loved it.. You have nailed it. You have defined common sense in a much much better way.
LikeLike